
本文参考公众号“运筹or帷幄”中文章,作者从数值优化和凸优化两个角度对两种算法进行了介绍,在此进行一个系统整理,以便后续学习。之前未曾接触过两个算法,只是看论文时看到了ADMM,想简单入门,因此知识比较基础,理解也比较粗浅,只是基于公众号文章的简单笔记整理。
本文思路为:先从数值优化的角度对两种算法进行初步理解,再从凸优化的角度进行再探,原文链接如下:
数值优化(C)——二次规划(下):内点法;现代优化:罚项法,ALM,ADMM;习题课优化│凸优化(A)——坐标下降法,对偶上升法,再看增强拉格朗日法凸优化(B)——再看交替方向乘子法(ADMM),Frank-Wolfe方法1.从对偶上升法看增强拉格朗日
2.坐标下降中的结尾部分飞灵:凸优化入门2:“运筹OR帷幄”凸优化(10)笔记总结
3.ADPMM(其中涉及到近端梯度法的理解,在凸优化(3)中有所涉及)
4.ADMM的并行应用
光滑优化本质是解决如下问题:
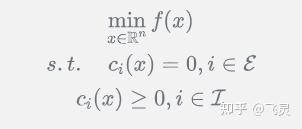
其中 均足够光滑。所以在一般的光滑优化里,对于约束和目标函数都没有很明显的形式限制,换句话说这是一个非常一般化的问题
罚项法的本质是通过罚项来转化优化问题,如对于图1中的光滑优化问题,只需构造如下的函数
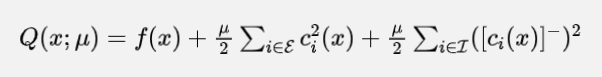
其中 。即对于不等式约束,只有对应值为负时才会有惩罚,而对于等式约束,只要其非零,就会产生惩罚,可以理解为一旦有“脱轨”的情况产生,就会产生惩罚。这样的处理就使一个有约束问题转化为了无约束问题。
下面的定理说明了该方法的可行性

如何理解该定理呢?图2中的 本质上就是惩罚的力度(可以理解为LASSO里的
),定理1的含义为,当该惩罚力度为无穷大时(
),求解出的x就是原始带约束问题(图1)的解(即函数的局部极小值点)。
但是该惩罚存在着一定的问题:
(1)即使我们最终做到了梯度趋于0,也就是算法收敛,我们也不一定能够保证收敛到一个可行解,该内容为定理2的含义

(2)海森矩阵性质差:即使我们的拉格朗日函数的海森矩阵性质很好, 很大的时候也无济于事,整个海森矩阵的特征值会呈现一个两极分化的状态。换句话说条件数很大,这个在数值优化中是一个大忌。总结一下就是说,对于所有依赖二阶信息的方法,都会呈现出很强的不稳定性
要解决这个问题,有一种方法就是改变罚项的性质,这一点非常像岭回归往LASSO的转换,就是把我们的2-范数罚项修改为1-范数罚项,也就是修改我们的函数为

修改过后,对应下面的定理成立

该定理的含义为:我们不需让 充分大,就可以找到函数的局部极小值点
将2-范数惩罚转化为1-范数惩罚后的优点在于不需 ,但同时函数也不光滑,为极小值求解带来困难,为此我们引入ALM方法。
和之前的罚项法不同的地方在于,它是针对函数对应的拉格朗日函数添加罚项,而不是针对目标函数本身。比方说对于一个等式约束问题
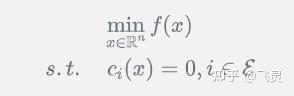
那么它的对应的增强拉格朗日函数就是
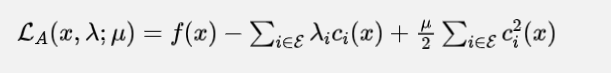
可以看出它就是一个拉格朗日函数加上罚项 的结果。那么这个时候,可以得到的是
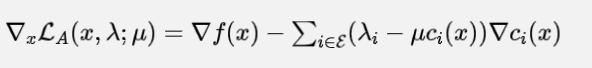
注意到当这个点 满足KKT条件时,如果我们设它对应的拉格朗日乘数为
,那么很明显无论
取多少,都有
。因此考虑下面一个迭代

此设计的思路为,一般来讲 是可以迭代且已知的,但
是未知的,所以对
进行迭代
具体的算法操作如下所示:(其中17.39指的是图7中的迭代公式)

(1)不需 就可找到解

(2)只要 足够靠近
,
就会足够靠近
,并且每一步迭代都会使得
与
的差距以线性收敛速度缩小,并且迭代点附近也有LICQ一样的性质。换句话说,我们的增广拉格朗日方法在实操中是可行的,毕竟数值优化算法的误差是不可避免的。

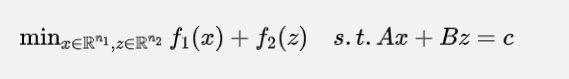

对于两个子函数的优化问题,我们的想法就是加上交替下降的思路,即每一次固定一个变量为常数,视作单变量的优化问题。然后再使用增广拉格朗日方法。具体的步骤如下:

即在第一步固定z为常数,最小化x,在第二步固定x,最小化z,在第三步固定x和z,最小化拉格朗日乘子s(s有的文章里也成为对偶变量)。这里的前两步就是交替下降法(坐标下降,详见:飞灵:凸优化入门2:“运筹OR帷幄”凸优化(10)笔记总结),也就是说每一步固定一个变量,只考虑与另外一个变量有关的项进行优化。第三步就是增广拉格朗日法,一直迭代到收敛为止即可。
ADMM方法的速度不算快(包括局部上的,这也算是一个缺点),如果 凸,那么它会有
的收敛速度。进一步的如果说是
强凸的,那么收敛速度就是线性的。但对于一阶方法而言,这已经够了。
(1)notation重述
由于和上面的部分来自于两篇文章,notation稍微有点不同,为了更清晰的理解,先重新说明一下notation
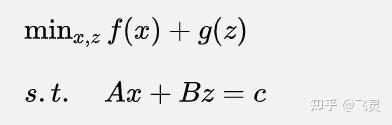


(2)标准化形式的ADMM
如果设 ,图12-2中拉格朗日函数会发生一些改动:
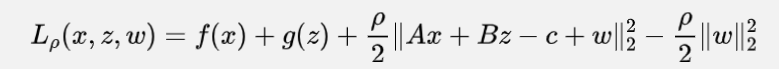
图15来自于经典开平方的逆运算,容易验证是和图12-2等价的。进行图13的改动过后,公式会变成下面的样子:
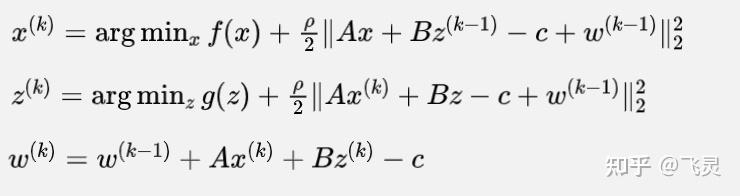
这么修改的好处也有一些,一是可以提出一个与 都无关的项
,所以优化的时候就可以直接无视它。二是在对
作更新的时候,其实等价于之前的
的更新式子再两边除以一个
。因此我们会发现在更新
的时候其实没有所谓的步长的说法了(回顾一下,在对偶上升法中,这个系数的意义就是步长),这也是“标准化形式”这个说法的由来。
(1)普通ADMM求解
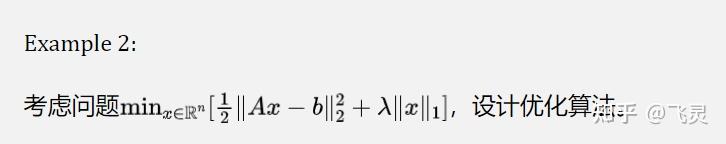
要使用ADMM方法,一个很重要的操作就是构造出两个相互不影响的函数。因此我们的想法就是设 ,所以这样的话问题就会变成
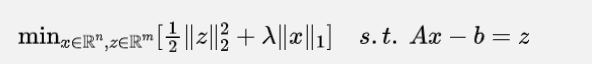
那么如果要使用ADMM,我们的迭代步骤就是:

这个计算的步骤也存在一些难点。对于第二个子问题,其实它是很容易找到显式解(closed-form)的,毕竟都是二次项,求个梯度然后设为0就好。但是对于第一个子问题, 的存在就使得问题的解没有一个固定的形式。不过这个问题也有解决的方案,这就是交替方向近端乘子法(Alternating Direction Proximal Method of Multipliers, ADPMM)。
(2)ADPMM求解
这个方法的思路来源于一阶方法中的近端梯度法,也就是加一个二阶项权重,使得问题的closed-form能够重现。也就是说
(3)标准化ADMM求解



按照ADMM的步骤,可知要对增广拉格朗日函数中先优化β,再优化α。
优化β即要解决如下问题:
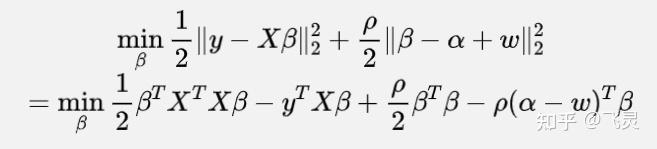
其中等号的原因就是将第一步中的平方乘开,去除常数项,整理可得等号后部分
让式子对β求梯度可得

因此不难得到 的更新公式,只需代入
即可
得到β的更新公式后,针对α进行优化,即考虑问题

其中,去除了 中很多含β项的原因在于ADMM中坐标下降法的思想,即在更新其中一个变量时,固定另一个变量,因此可将另一个变量看为常数。
α目标函数即为近端梯度法(优化│凸优化(4)——次梯度案例,加速梯度法,随机梯度下降法,近端梯度法引入 example2)的软阈值算子,因此可轻松求解
最终的迭代公式为:
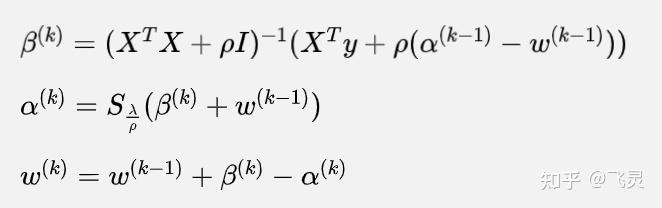
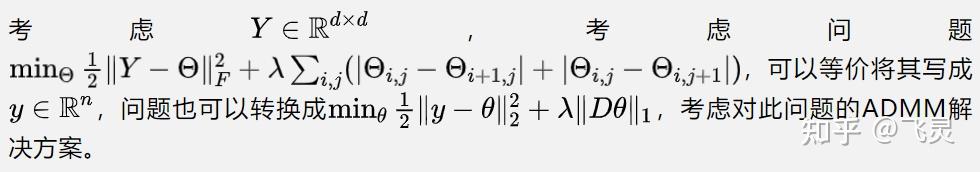
这里的2d含义是指两个罚项分别是针对x,y坐标来做的,即 代表对x坐标的惩罚,
代表对y坐标的惩罚
如何将该问题从无约束优化转化为约束优化,再使用ADMM呢?这里有两种思路
(1)设
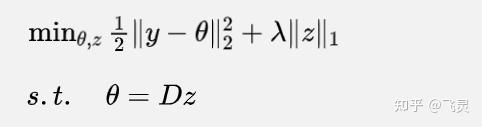
这样的话可以把ADMM的迭代公式写为

(2)将 拆分为
两个

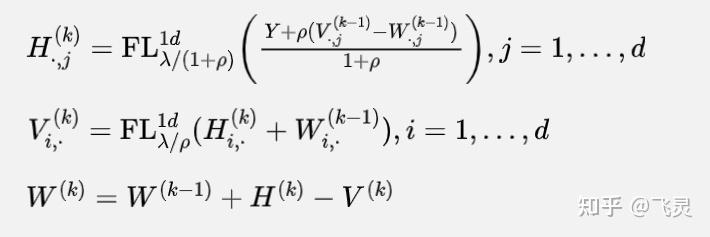
这里H是一列一列更新,而V是一行一行更新的
此部分内容参考:
华年ss:中科大凸优化51-52:交替方向乘子法考虑如下问题(Consensus问题):
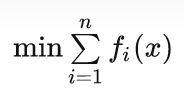
即将前面简单问题中仅考虑 两个函数相加拓展成
个函数相加,求解过程如下:

通过上述迭代可以看出,更新 时,至于下标为
的变量有关,与
无关,即
个下标索引的计算可以分配到
台计算机/线程/进程分别进行计算,只在更新
,需要汇总各个计算节点的数据,更新
后,再将结果分发到各个节点,从而实现分布式计算

公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

